W statystyce najtrudniejsze nie jest samo policzenie wyniku, ale uczciwe powiedzenie, jak dużą mamy co do niego pewność. Przedział ufności to narzędzie, które pozwala opisać, jak szeroki jest realistyczny zakres wartości dla parametru populacji, gdy pracujemy na próbie. W tym tekście pokazuję, jak go czytać, jak go policzyć, od czego zależy jego szerokość i gdzie najczęściej pojawiają się błędy interpretacyjne.
Najkrócej: czego naprawdę dotyczy to pojęcie
- To zakres wartości, w którym szacujemy nieznany parametr populacji, a nie pojedynczy wynik z próby.
- Najważniejsze są trzy rzeczy: liczebność próby, zmienność danych i wybrany poziom ufności.
- Najczęściej spotkasz poziom 95%, ale 99% daje szerszy i ostrożniejszy zakres.
- Przy średniej z małej próby zwykle korzysta się z rozkładu t-Studenta.
- Najczęstszy błąd to mylenie interpretacji zakresu z prawdopodobieństwem dla konkretnej wartości w populacji.
Co ten zakres mówi o danych
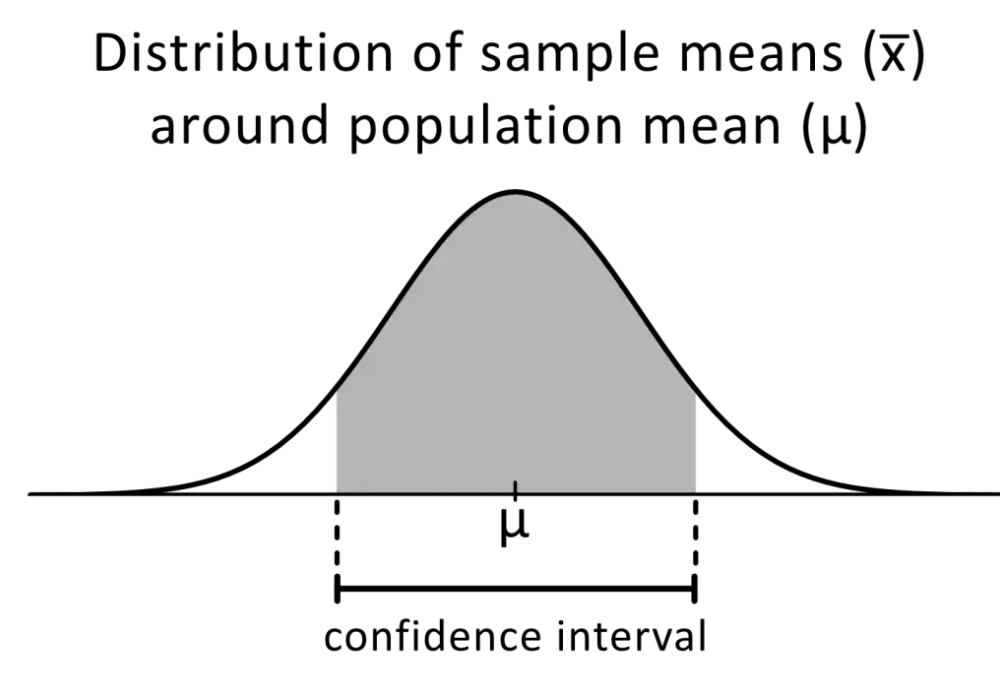
Ja zwykle tłumaczę to tak: z jednej liczby z próby dostaję oszacowanie punktowe, ale dopiero zakres wokół niej pokazuje, jak stabilny jest ten wynik. Jeśli średnia z klasy wynosi 4,2, to sama średnia mówi niewiele o niepewności. Dopiero przedział pokazuje, czy rzeczywisty parametr populacji może leżeć bardzo blisko tej wartości, czy raczej w dość szerokim obszarze.
W praktyce nie opisuję więc „gdzie znajduje się wynik próbki”, tylko jaką wartość może mieć parametr całej populacji. To ważne rozróżnienie, bo wiele osób instynktownie interpretuje taki zakres jako coś w rodzaju gwarancji dla pojedynczych obserwacji. Tak nie działa statystyka. Ten zakres dotyczy parametru, na przykład średniej, odsetka albo wariancji, a nie każdego pojedynczego ucznia, klienta czy pomiaru.
W edukacji najłatwiej pokazać to na prostym przykładzie. Jeśli badam wzrost grupy uczniów i z próby wychodzi średnia 168 cm, to zakres ufności nie mówi, że „większość uczniów ma 168 cm”. Mówi raczej, że średni wzrost w całej populacji uczniów z tej szkoły najpewniej mieści się w określonych granicach. To jest różnica, którą trzeba umieć nazwać bez wahania, bo od niej zależy cała dalsza interpretacja.
Z tej perspektywy łatwiej przejść do samego liczenia, bo wtedy widać, skąd biorą się granice i dlaczego czasem są wąskie, a czasem zaskakująco szerokie.
Jak go policzyć krok po kroku
W praktyce liczę to w tej kolejności: najpierw wybieram parametr, potem sprawdzam typ danych, a dopiero na końcu dobieram wzór. Dla średniej wygląda to zwykle tak: estymator punktowy ± wartość krytyczna × błąd standardowy. Jeśli odchylenie standardowe populacji jest nieznane, najczęściej używam rozkładu t-Studenta; jeśli znamy je albo pracujemy na odpowiednio dużej próbie, można oprzeć się na przybliżeniu normalnym.
- Wybieram parametr, który chcę oszacować: średnią, odsetek, wariancję albo różnicę między dwiema grupami.
- Obliczam estymator punktowy, czyli pojedynczą liczbę z próby.
- Sprawdzam liczebność próby i rozkład danych.
- Ustalam poziom ufności, najczęściej 95%.
- Dobieram wartość krytyczną: z albo t.
- Wyznaczam margines błędu i zapisuję dolną oraz górną granicę.
Dla średniej z próby, gdy odchylenie populacyjne jest nieznane, zapis jest najczęściej taki: x̄ ± t × s/√n. Tu x̄ to średnia z próby, s to odchylenie standardowe z próby, n to liczebność, a t to wartość krytyczna z rozkładu t-Studenta. Dla odsetka korzysta się zwykle z zapisu p̂ ± z × √(p̂(1-p̂)/n), gdzie p̂ oznacza udział zaobserwowany w próbie.
Jeśli ktoś dopiero zaczyna, polecam zapamiętać jedną rzecz: nie ma jednego uniwersalnego wzoru na wszystko. Inny zapis stosuje się dla średniej, inny dla proporcji, a jeszcze inny dla wariancji. To prowadzi nas wprost do pytania, od czego właściwie zależy szerokość wyniku.
Od czego zależy jego szerokość i dlaczego wynik bywa zaskakująco szeroki
Ja patrzę na cztery rzeczy: liczebność próby, zmienność danych, poziom ufności i jakość założeń. To one decydują, czy dostajemy wąski, użyteczny zakres, czy raczej szeroki pas, który mówi tylko tyle, że „wiemy niewiele”.
| Co wpływa na wynik | Jak działa | Co z tego wynika praktycznie |
|---|---|---|
| Większa próba | Zmniejsza błąd standardowy | Zakres zwykle się zwęża |
| Większa zmienność | Podnosi niepewność oszacowania | Zakres staje się szerszy |
| Wyższy poziom ufności | Wymaga bardziej ostrożnych granic | 99% daje szerszy zakres niż 95% |
| Outliery i błędy pomiaru | Rozstrajają estymację | Wynik może być mniej wiarygodny niż sugerują same liczby |
Najbardziej intuicyjny jest wpływ liczebności próby. Gdy n rośnie, błąd standardowy zwykle maleje, więc zakres staje się ciaśniejszy. Dlatego mała próba bardzo często daje wynik, który wygląda „nieelegancko” szeroko, ale to nie wada wzoru, tylko uczciwy sygnał, że danych jest za mało.
Drugi ważny czynnik to poziom ufności. Jeśli podnoszę go z 95% do 99%, dostaję większą ostrożność, ale płacę za nią szerszym zakresem. To normalny kompromis. Nie da się jednocześnie żądać bardzo wysokiej pewności i bardzo wąskiego przedziału bez zwiększenia liczby obserwacji albo poprawy jakości danych.
Ten temat naturalnie prowadzi do wyboru właściwego rozkładu, bo w zależności od sytuacji używa się innego narzędzia obliczeniowego.
Kiedy używam t-Studenta, a kiedy rozkładu normalnego
W pracy dydaktycznej najczęściej rozdzielam te dwa przypadki bardzo prosto. Jeśli odchylenie standardowe populacji jest nieznane, a próbka jest mała, sięgam po t-Studenta. Jeśli próba jest duża, a dane nie sprawiają kłopotów, rozkład normalny bywa wystarczającym przybliżeniem. To nie jest ozdobna teoria, tylko praktyczny wybór, który wpływa na końcowe granice.
| Sytuacja | Co zwykle stosuję | Dlaczego |
|---|---|---|
| Średnia, mała próba, σ nieznane | t-Student | Uwzględnia większą niepewność estymacji |
| Średnia, duża próba | Przybliżenie normalne | Rozkład średniej stabilizuje się wraz z n |
| Odsetek z badania | Przybliżenie normalne dla proporcji | Dobrze działa przy wystarczającej liczbie sukcesów i porażek |
| Wariancja | Rozkład chi-kwadrat | Parametr rozrzutu liczy się inaczej niż średnią |
Przy proporcjach warto pilnować prostego warunku technicznego: jeśli w próbie jest zbyt mało sukcesów albo zbyt mało porażek, przybliżenie normalne może być słabe. Wtedy lepiej zachować ostrożność i rozważyć inną metodę. Ja w takich sytuacjach wolę napisać uczciwie, że klasyczny wzór ma ograniczenia, niż udawać, że wszystko działa bez zastrzeżeń.
Stąd już tylko krok do typowych pomyłek, bo właśnie tutaj uczniowie i początkujący analitycy potykają się najczęściej.
Gdzie najłatwiej popełnić błąd
Najczęściej widzę dwa błędy. Pierwszy to traktowanie wyniku jak prawdopodobieństwa dla konkretnej wartości po fakcie. Drugi to mylenie zakresu dla parametru z zakresem dla pojedynczych obserwacji. Oba prowadzą do złej interpretacji, nawet jeśli obliczenia są formalnie poprawne.
- Błąd 1: „95% szans, że parametr leży dokładnie w tym jednym przedziale” po wyliczeniu. Lepiej mówić, że metoda ma 95% pokrycia w długim okresie powtarzania badań.
- Błąd 2: „95% danych znajduje się w granicach”. To nie jest opis rozrzutu obserwacji, tylko oszacowania parametru.
- Błąd 3: Pomijanie outlierów i zakładanie, że nie mają znaczenia. Przy małej próbie jeden skrajny wynik potrafi mocno przesunąć granice.
- Błąd 4: Zbyt wczesne zaokrąglanie. Na końcu można zaokrąglić wynik, ale w trakcie obliczeń lepiej zachować więcej miejsc po przecinku.
- Błąd 5: Użycie złego wzoru do typu danych. Średnia, odsetek i wariancja nie są tym samym problemem statystycznym.
Jeśli mam podać jedną praktyczną radę, to brzmi ona tak: zawsze dopisuj jedno zdanie interpretacji własnymi słowami. Sam wynik liczbowy nie wystarcza. W zadaniach szkolnych to często właśnie to zdanie decyduje o tym, czy widać, że ktoś naprawdę rozumie sens obliczeń, a nie tylko odtworzył wzór.
To prowadzi do kolejnego częstego nieporozumienia, czyli mieszania zakresu ufności z poziomem istotności i p-value.
Jak odróżnić go od poziomu istotności i p-value
Ja porządkuję to tak: poziom ufności mówi, jak ostrożny chcę być przy budowie zakresu, a poziom istotności określa próg decyzji w teście hipotez. To są pojęcia spokrewnione, ale nie tożsame. P-value z kolei mówi, jak bardzo dane są zgodne z hipotezą zerową, a nie gdzie leży parametr.
| Pojęcie | Co opisuje | Najczęstsza pomyłka |
|---|---|---|
| Poziom ufności | Jak szeroki i ostrożny ma być zakres | Mylenie go z prawdopodobieństwem dla jednej konkretnej liczby |
| Poziom istotności α | Jak mały błąd I rodzaju akceptuję w teście | Traktowanie go jak „szansy, że hipoteza jest prawdziwa” |
| p-value | Jak nietypowe są dane przy założeniu hipotezy zerowej | Uznawanie go za miarę wielkości efektu |
Przy dwustronnym teście na poziomie 0,05 a 95-procentowy zakres są ze sobą ściśle powiązane: jeśli wartość z hipotezy zerowej nie mieści się w takim zakresie, zwykle odrzucamy hipotezę na poziomie 0,05. To jednak nie znaczy, że oba pojęcia są zamienne. Jeden służy do opisu niepewności estymacji, drugi do decyzji testowej.
Na lekcjach i sprawdzianach ta różnica często robi największą różnicę. Jeśli ktoś umie ją jasno wyjaśnić, to znaczy, że naprawdę rozumie temat, a nie tylko operuje symbolami.
Krótka checklista do zadań i obliczeń
Gdy rozwiązuję zadanie, sprawdzam zawsze te same rzeczy. To oszczędza czas i zmniejsza ryzyko banalnego błędu.
- Najpierw ustalam, czy liczę dla średniej, odsetka, wariancji czy różnicy między grupami.
- Potem sprawdzam, czy znam odchylenie populacyjne, czy muszę je zastąpić estymatorem z próby.
- Wybieram właściwy rozkład i nie mieszam go z innym tylko dlatego, że wzór wygląda podobnie.
- Nie zaokrąglam zbyt wcześnie, zwłaszcza przy liczeniu błędu standardowego i wartości krytycznej.
- Na końcu dopisuję interpretację w języku naturalnym, a nie sam wynik liczbowy.
Jeśli chcesz zapamiętać tylko jedną rzecz, zapamiętaj tę: dobrze policzony zakres nie jest jeszcze pełną odpowiedzią, dopóki nie umiesz go poprawnie opisać. W statystyce sama arytmetyka to dopiero połowa pracy, a druga połowa to sensowna interpretacja tego, co liczby naprawdę mówią o populacji.