Wariancja to jedna z najważniejszych miar rozproszenia danych, bo pokazuje, jak mocno wyniki odbiegają od średniej. W praktyce szkolnej i analitycznej pomaga odróżnić zbiór „równy” od takiego, w którym wartości są bardzo porozrzucane. Poniżej wyjaśniam, jak ją policzyć, jak odczytać wynik i kiedy lepiej sięgnąć po inną miarę.
Najważniejsze fakty o rozproszeniu danych w jednym miejscu
- Ta miara opisuje rozrzut wartości wokół średniej, a nie ich „jakość”.
- Wynik jest zawsze nieujemny, bo liczy się go z kwadratów odchyleń.
- Jednostka wyniku jest podniesiona do kwadratu, więc sama liczba bywa mało intuicyjna.
- W analizie próby i całej populacji stosuje się różne mianowniki.
- Do codziennej interpretacji często wygodniejsze jest odchylenie standardowe.
- Przy porównywaniu grup o różnych skalach warto patrzeć także na miary względne.
Co naprawdę pokazuje ta miara
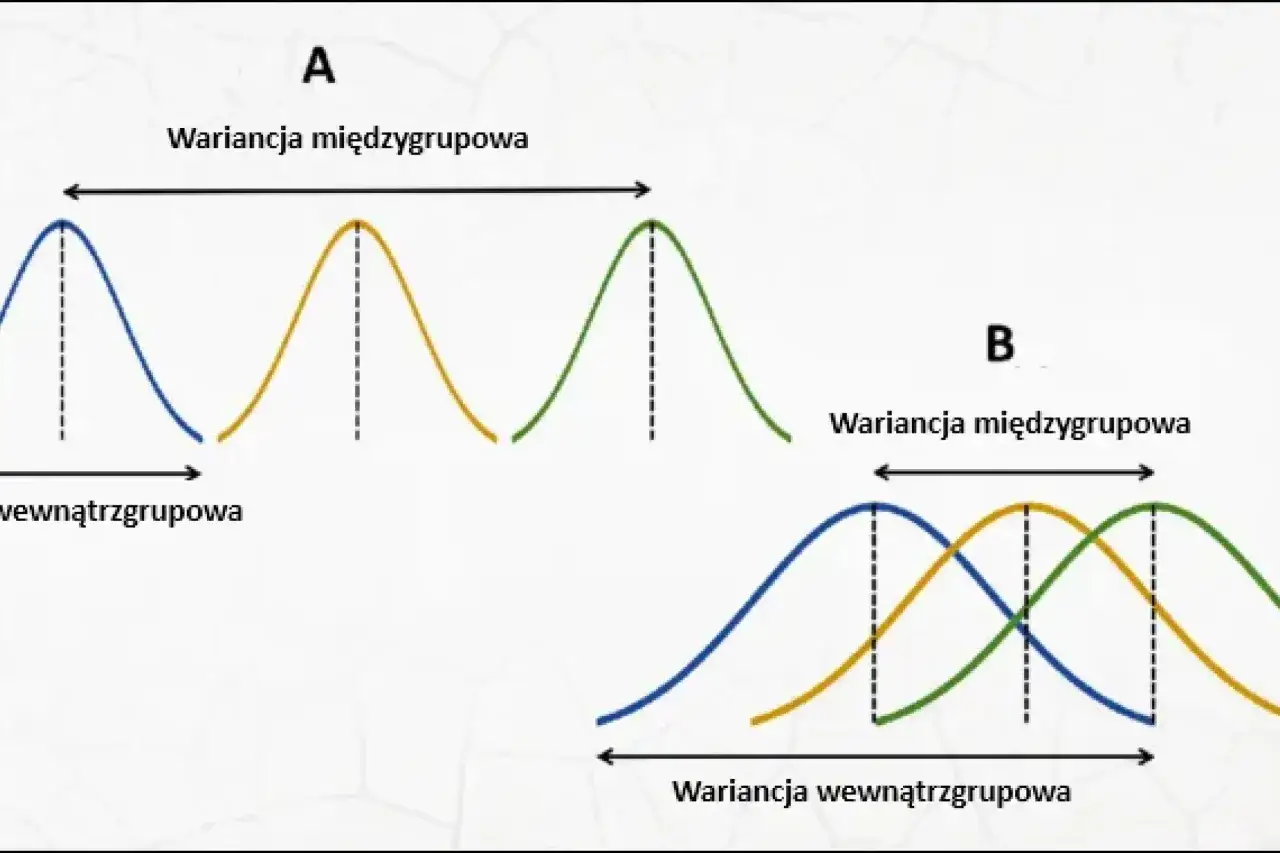
Najkrócej mówiąc, chodzi o to, czy dane skupiają się blisko średniej, czy rozchodzą się daleko od niej. Ja traktuję tę miarę jako sygnał zmienności: im większa, tym bardziej rozchwiane są wartości w zbiorze. To ważne, bo dwa zestawy mogą mieć identyczną średnią, a zupełnie inny rozrzut.
W obliczeniach nie sumuje się zwykłych odchyleń od średniej, tylko ich kwadraty. Dzięki temu dodatnie i ujemne różnice nie znoszą się nawzajem. Efekt uboczny jest taki, że wynik ma jednostkę w kwadracie, na przykład zł2, cm2 albo punkty2, więc bez dodatkowego komentarza nie brzmi zbyt naturalnie.
To właśnie dlatego w statystyce opisowej tak często mówi się o „rozproszeniu” albo „zróżnicowaniu”, a nie o samej liczbie. Żeby zobaczyć to bez abstrakcji, przejdźmy do rachunku na konkretnych danych.
Jak policzyć wariancję krok po kroku
Wzór jest prosty, jeśli rozbijesz go na etapy. Najpierw liczysz średnią, potem odejmujesz ją od każdej obserwacji, następnie podnosisz różnice do kwadratu, sumujesz i dzielisz przez odpowiedni mianownik.
Dla całej zbiorowości
Jeśli masz wszystkie wartości z badanego zbioru, korzystasz z zapisu: σ2 = Σ(xi - μ)2 / N. W praktyce oznacza to: suma kwadratów odchyleń od średniej podzielona przez liczbę obserwacji.
Przeczytaj również: Jak się pisze skóra? Uniknij powszechnych błędów w pisowni
Dla próby
Jeśli pracujesz tylko na fragmencie większego zbioru, często stosuje się s2 = Σ(xi - x̄)2 / (n - 1). To tzw. korekta Bessela, czyli poprawka, która ogranicza zaniżanie wyniku przy małej próbie. W szkolnych zadaniach to bardzo częsty wariant i warto sprawdzać, który mianownik autor zadania miał na myśli.
Dla danych 2, 4, 4, 4, 5, 5, 7, 9 średnia wynosi 5. Jeśli uznasz je za całą populację, wynik wynosi 4; jeśli potraktujesz je jako próbę, dostaniesz około 4,57. Dla odchylenia standardowego byłyby to odpowiednio 2 i około 2,14.
| xi | xi - x̄ | (xi - x̄)2 |
|---|---|---|
| 2 | -3 | 9 |
| 4 | -1 | 1 |
| 4 | -1 | 1 |
| 4 | -1 | 1 |
| 5 | 0 | 0 |
| 5 | 0 | 0 |
| 7 | 2 | 4 |
| 9 | 4 | 16 |
| Suma | 32 |
Sam rachunek jest już jasny, ale najłatwiej popełnić błąd przy interpretacji. Dlatego zaraz zestawiam tę miarę z odchyleniem standardowym.
Jak odróżnić tę miarę od odchylenia standardowego
W praktyce te dwa pojęcia są ze sobą nierozerwalne, ale nie pełnią tej samej roli. Jedno jest bardziej „techniczne”, drugie łatwiej tłumaczyć ludziom bez przygotowania statystycznego.
| Miara | Co pokazuje | Jednostka | Kiedy jej używam |
|---|---|---|---|
| Miara oparta na kwadratach | Rozrzut wokół średniej | Kwadrat jednostki | Obliczenia, modele, analiza matematyczna |
| Odchylenie standardowe | Typowy dystans od średniej | Taka sama jak w danych | Prostsza interpretacja wyniku |
| Rozstęp | Różnica między minimum i maksimum | Taka sama jak w danych | Szybki, orientacyjny opis |
Jeśli chcę szybko opisać wynik rodzicowi, nauczycielowi albo uczniowi, zwykle sięgam po odchylenie standardowe, bo ma tę samą jednostkę co dane. Jeśli natomiast liczę coś dalej, na przykład w modelu statystycznym, sama miara oparta na kwadratach bywa wygodniejsza. Przy porównywaniu grup o różnych średnich przydaje się jeszcze współczynnik zmienności, bo pokazuje rozrzut względny, a nie tylko bezwzględny.
To prowadzi do ważniejszego pytania: po co w ogóle analizować rozrzut, skoro średnia już coś nam mówi?
Dlaczego sama średnia może mylić
Dwa zbiory mogą mieć identyczną średnią i zupełnie inną historię. Weźmy przykład klasowy: w pierwszej grupie wszystkie oceny to 5, w drugiej są to 2, 4, 6 i 8. W obu przypadkach średnia wynosi 5, ale pierwszy zestaw jest idealnie równy, a drugi pokazuje duże wahania. To nie jest drobiazg, tylko realna różnica w obrazie danych.
Ja zwracam na to uwagę szczególnie przy wynikach z testów, ankiet i pomiarów. Średnia 70% może oznaczać stabilną grupę uczniów albo rozbitą na dwa skrajne obozy klasę. Dopiero miara rozproszenia pokazuje, czy wynik jest typowy dla większości, czy tylko „maskuje” skrajności.
- Jeśli średnia jest wysoka, ale rozrzut też duży, zbiór bywa nierówny i trudno mówić o stabilności wyników.
- Jeśli średnia jest umiarkowana, ale rozrzut mały, wartości są przewidywalne i bliskie siebie.
- Jeśli rozrzut jest zerowy, wszystkie obserwacje są identyczne i nie ma żadnej zmienności.
W praktyce właśnie tu najczęściej pojawia się złudzenie: dobra średnia nie zawsze oznacza dobry obraz danych. Następny krok to sprawdzenie, jakie błędy najczęściej psują interpretację.
Najczęstsze błędy przy obliczeniach i interpretacji
- Mieszanie populacji z próbą. Jeśli liczysz cały zbiór, mianownik jest inny niż wtedy, gdy analizujesz tylko próbkę. To jeden z najprostszych sposobów, by dostać wynik „prawie dobry”, ale jednak niepoprawny.
- Uśrednianie samych odchyleń. Bez kwadratów dodatnie i ujemne różnice zniosłyby się nawzajem, a wynik mógłby wyjść bliski zeru nawet przy dużym rozrzucie.
- Porównywanie danych w różnych jednostkach bez ostrożności. Inaczej czyta się złotówki, inaczej punkty, a jeszcze inaczej centymetry. Sama liczba nie wystarcza bez kontekstu.
- Ignorowanie wartości odstających. Jeden bardzo duży lub bardzo mały wynik może mocno podbić rozrzut i zmienić obraz całego zbioru.
- Stosowanie tej miary do nieodpowiedniego typu danych. Najlepiej działa dla danych ilościowych; przy danych porządkowych i kategorycznych trzeba zachować ostrożność.
Gdy pilnuję tych pięciu rzeczy, wynik zaczyna być naprawdę użyteczny, a nie tylko poprawny rachunkowo. Na końcu zostaje już praktyczna kwestia: jak korzystać z tej wiedzy w szkolnych zadaniach i prostych analizach.
Na co zwracam uwagę, gdy rozrzut zaczyna mieć znaczenie
- Najpierw sprawdzam, czy opisuję całą zbiorowość, czy tylko jej fragment.
- Potem patrzę, czy wynik ma mi pomóc w obliczeniach, czy w prostym wyjaśnieniu danych.
- Jeśli porównuję kilka grup, nie zatrzymuję się na średniej, tylko sprawdzam też rozproszenie i liczebność.
- Przy wynikach klasowych, ankietowych i pomiarowych szukam skrajnych obserwacji, bo potrafią mocno zmienić obraz całości.
- Gdy potrzebuję ocenić względną zmienność, rozważam współczynnik zmienności zamiast samej wartości bezwzględnej.
To właśnie taki zestaw prostych nawyków sprawia, że statystyka przestaje być zbiorem wzorów, a zaczyna pomagać w realnym czytaniu danych. Jeśli ktoś rozumie, co oznacza rozrzut, średnia przestaje być jedyną liczbą wartą uwagi, a wyniki stają się znacznie bardziej uczciwe wobec rzeczywistości.